C-Accel Pilot - Track A1 (Open Knowledge Network)
Project BONDS: Integrated Biomedical Open Knowledge Networks for Health Data Science Ecosystem
Project Description The application of data science in the health domain has the potential to revolutionize our knowledge about health, as well as the practice of healthcare. This is because a wide variety of organizations, including health care providers, pharmaceutical companies, health insurance companies, and government agencies are already generating a substantial amount of data. To help make sense of such data, a large number of biomedical knowledge networks have been developed.
Challenges and opportunities: Despite various data science successes, biomedical knowledge networks have yet to demonstrate significant value to support biomedical data science. In particular, existing knowledge networks are limited in several critical aspects:
- Incorporating new knowledge: Most existing ontologies are created in batch and are rarely comprehensive. However, new knowledge is discovered rapidly, such that knowledge networks become outdated almost instantly. This partially explains why there is limited usage of such networks for data science projects.
- Knowledge embedding: Modern data science methods, such as deep learning, often require machine-friendly knowledge representations, such as embedding vectors that capture latent relations among concepts. Unfortunately, standard ontologies do not directly provide such representation.
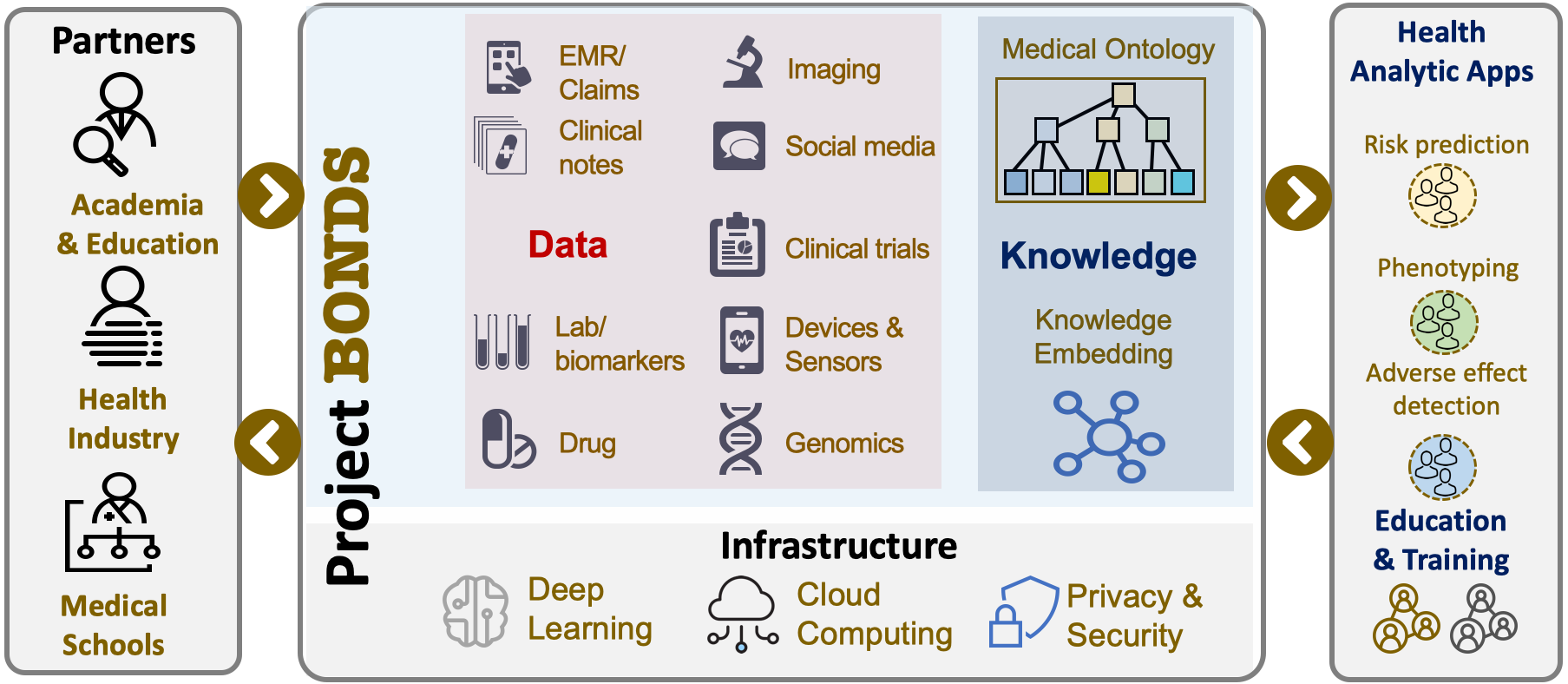
- Diverse biomedical data: To realize real impact, biomedical knowledge networks need to be derived from all data modalities, including, but necessarily limited to, observational longitudinal data, spontaneous reporting systems, clinical trials data, the medical literature and guidelines, patient discussion forums, genomic data and mobile sensor data.
- Cross-institution collaboration: Valuable biomedical data are often kept within the walls of an organization. Despite their value, data sharing between organizations is difficult to realize, due to various concerns over patient privacy, data security and intellectual property, although knowledge networks can be constructed without sharing the raw data.
We propose to create the Biomedical Open knowledge Network for Data Science (BONDS) lab. This will behosted in the cloud to enable rapid creation and execution of data science projects on both public and proprietary data sources from multiple institutions. BONDS will provide a secure open cloud-based platform. In doing so, it will provide an opportunity to grow a community of biomedical researchers and practitioners to collaborate by sharing ideas, problems, and leverage/enhance existing biomedical knowledge networks to achieve different objectives in education, research, industry applications. BONDS will be guided by several specific objectives:
- Data resources: Data are the essential raw materials to support all data science projects. Given the sensitivity of biomedical data (e.g., electronic health records), BONDS will provide cloud based data repositories of multiple security levels to support diverse data science activities. In particular, recognizing the challenge to share sensitive data, BONDS will generate synthetic but realistic data for supporting training activities for public. Also the real and sensitive data are still used for sponsored projects.
- Knowledge resource: Biomedical knowledge networks including medical ontologies for human and concept embeddings for machines will be continuously updated by various projects. For example, new concepts and relations can be proposed and new concept embeddings can be shared from each project to the public knowledge networks.
- Data science market: Successful data science projects require qualified interdisciplinary teams including domain experts, health data providers, and machine learning experts to work towards concrete well-design objectives. We plan to implement a dynamic market place to form and facilitate data science competitions in the biomedical space, which the project sponsors can benefit from by solving important problems with researchers. Also, these competitions will enable researchers to use open biomedical knowledge networks and enhance them based on the needs of real data science applications.
- Workforce education: As knowledge networks constantly evolve, health data scientists needs to acquire up-to-date information and practices in both computational skills and domain knowledge. BONDSwill provide a training playground for data scientists to continuously learn from open knowledge networks and grow their skills through real world projects. These opportunities will be supported through diverse educational activities, including MOOCs, tutorials, and data science hackathons.
Core Team
Jimeng Sun (PI, Georgia Tech) is an associate professor in college of computing specialized in data mining and machine learning for healthcare applications.
Brad Malin (co-PI, Vanderbilt University School of Medicine) is a Professor of Biomedical informatics, Biostatistics, and Computer Science with expertise in data privacy and security.
Cao (Danica) Xiao (co-PI, IQVIA Inc.) is the director of machine learning at IQVIA specialized in deep phenotyping and graph neural networks for in-silico drug modeling.
Chengxiang Zhai (co-PI, UIUC CS) is the Donald Biggar Willett Professor in Engineering at UIUC specialized in Intelligent Information Systems (e.g., intelligent search engines, recommender systems, text analysis engines, and intelligent task assistants).